内存分层体系
内存的分层体系:运行内存(主存) / 磁盘(虚拟内存)。主存是在运行程序时所需要保存的数据空间,而磁盘是用于持久化数据保存的数据空间。
CPU 可以访问的内存包括两大类 : 寄存器 / cache (L1缓存 / L2缓存)。大体的调用关系如下, 首先要考虑最为快速的缓存,其存取速度与 CPU 主频相同。缓存的使用是我们所不能意识到的,因为其依靠硬件实现。但内存和虚存是我们需要在操作系统当中操作的。
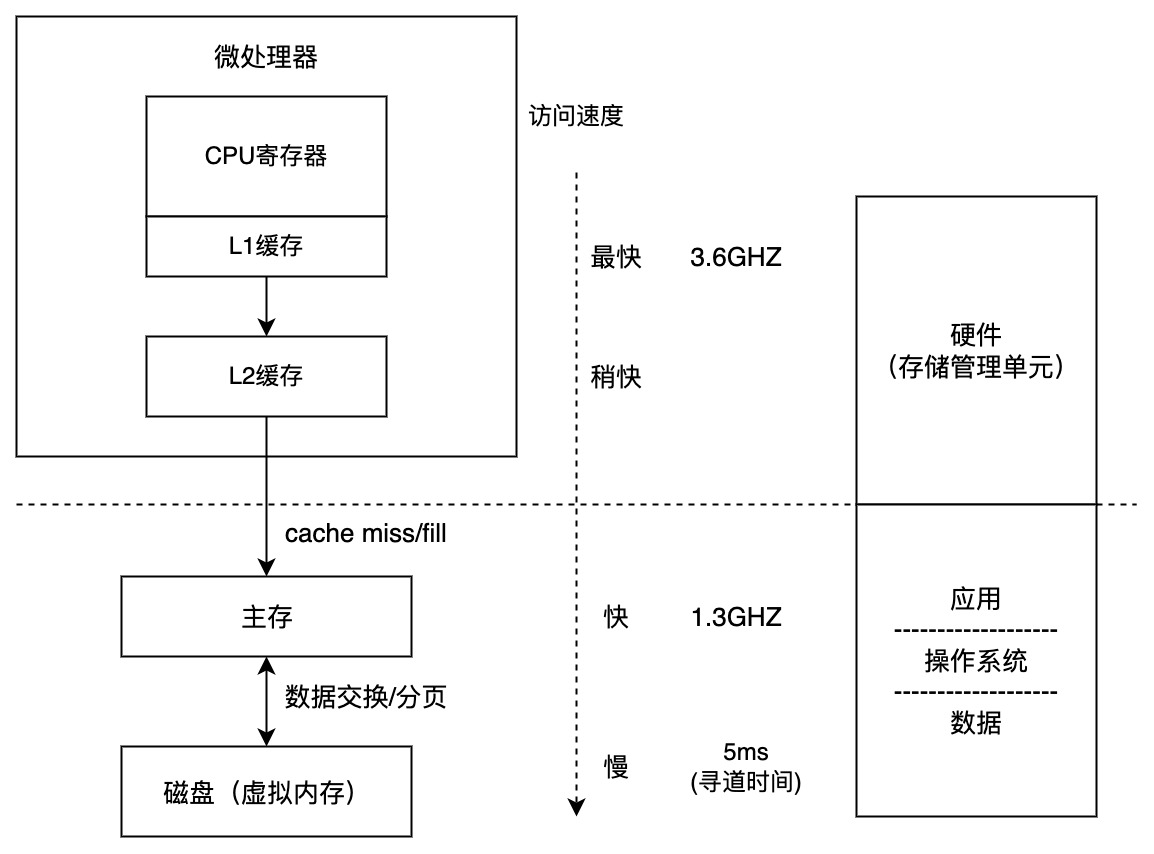
逻辑地址空间:物理地址如果交由计算机或许是可以方便使用的,但是对于人来说,并不容易记忆理解和使用。我们希望各个进程使用的存储都相对性地低耦合,有一个比较清晰的逻辑结构,于是就把线性的物理地址编号转换为抽象的逻辑内存结构的管理机制是 MMU(Memory Management Unit,即存储管理单元,也叫做内存管理单元)。
内存管理目标
- 抽象:逻辑地址空间
- 保护:独立地址空间
- 共享:访问相同内存
- 虚拟化:更多的地址空间
内存管理方法
- 程序重定位(relocation)
- 分段(segmentation)
- 分页(paging)
- 虚拟内存(virtual memory)
实现高度依赖于硬件, 其中内存管理单元(MMU)负责处理 CPU 的内存访问请求。
地址空间和地址生成
物理空间地址:硬件支持的地址空间,起始地址为 0,直到 MAXsys 逻辑地址空间:在 CPU 运行的进程看到的地址,起始地址同样为 0,直到 MAXprog
地址生成
ALU(算术逻辑单元)所需要的地址是逻辑地址,但向内存中取用时,需要的是物理地址。CPU 中依靠 MMU 进行一次逻辑到物理地址的转换。虽然这是硬件完成的,但是操作系统提供两者之间的关系的映射,而后还要进行地址检查,防止超过段长度。如果超过,加上段基址完成重定位即可。
即逻辑地址到物理地址的转换。
连续内存分配
连续内存分配,即给进程分配一块不小于指定大小的连续物理内存区域。
内存碎片
内存碎片问题指的是空闲的内存无法被利用,主要分为以下两种:
- 外部碎片 : 分配单元之间未使用的内存。
- 内部碎片 : 分配单元内的未使用内存,取决于分配单元大小是否要取整。
分区的动态分配策略
分区的动态分配方式有以下三种 :
- 第一匹配分配(first fit) : 在内存中找到第一个比需求大的空闲块, 分配给应用程序
- 最优适配分配(best-fit) : 在内存中找到最小的空闲块, 分配给应用程序
- 最差适配分配(worst-fit) : 在内存中找到最大的空闲块, 分配给应用程序
分配方式的区别和优缺点:
| 分配方式 | 第一匹配分配 | 最优适配分配 | 最差适配分配 |
|---|---|---|---|
| 分配方式 | 1. 按地址排序的空闲块列表 2. 分配需要寻找一个合适的分区 3. 重分配需要检查是否可以合并相邻空闲分区 | 1. 按尺寸排序的空闲块列表 2. 分配需要寻找一个合适的分区 3. 重分配需要检查是否可以合并相邻空闲分区 | 1. 按尺寸排序的空闲块列表 2. 分配最大的分区 3. 重分配需要检查是否可以合并相邻空闲分区 |
| 优势 | 简单 / 易于产生更大空闲块 | 比较简单 / 大部分分配是小尺寸时高效 | 分配很快 / 大部分分配是中尺寸时高效 |
| 劣势 | 产生外部碎片 / 不确定性 | 产生外部碎片 / 重分配慢 / 产生很多没用的微小碎片 | 产生外部碎片 / 重分配慢 / 易于破碎大的空闲块以致大分区无法被分配 |
三种分配方式并无优劣之分,因为我们无法判断内存请求的大小。
碎片整理方法
可以看到的是,三种分区动态分配的方式都会产生外部碎片,因此我们可以对碎片进行一定的整理来解决碎片问题。
1. 压缩式碎片整理
- 重置程序以合并碎片
- 要求所有程序是动态可重置的
- 问题:
- 何时重置 ? (在程序处于等待状态时才可以重置)
- 需要考虑内存拷贝的开销
2. 交换式碎片整理
- 运行程序需要更多的内存时,抢占等待的程序并且回收它们的内存
- 问题:如何判断哪些程序应该被回收 ?
非连续内存分配
我们知道,操作系统加载到内存以及程序加载到内存中时, 分配一块连续的内存块容易出现碎片问题,而非连续内存分配可以有效的减少碎片的出现。非连续内存分配有以下几个优点:
- 一个程序的物理地址空间是非连续的
- 更好的内存利用和管理
- 允许共享代码与数据(共享库等…)
- 支持动态加载和动态链接
缺点:
如何建立虚拟地址和物理地址的转换
- 软件方案:开销大
- 硬件方案:分段 / 分页
分段存储管理(segmentation)
段表示访问方式和存储数据等属性相同的一段地址空间,对应一个连续的内存“块”,由若干个“段”组成进程逻辑地址空间。进程的地址空间由多个功能不同的段构成:主代码段、子模块代码段、公用库代码段、stack、heap、初始化数据段、符号表等。将各个功能区隔离开之后,段式存储就实现了更细粒度的灵活的分离与共享。段式存储在做内存保护方面有优势。
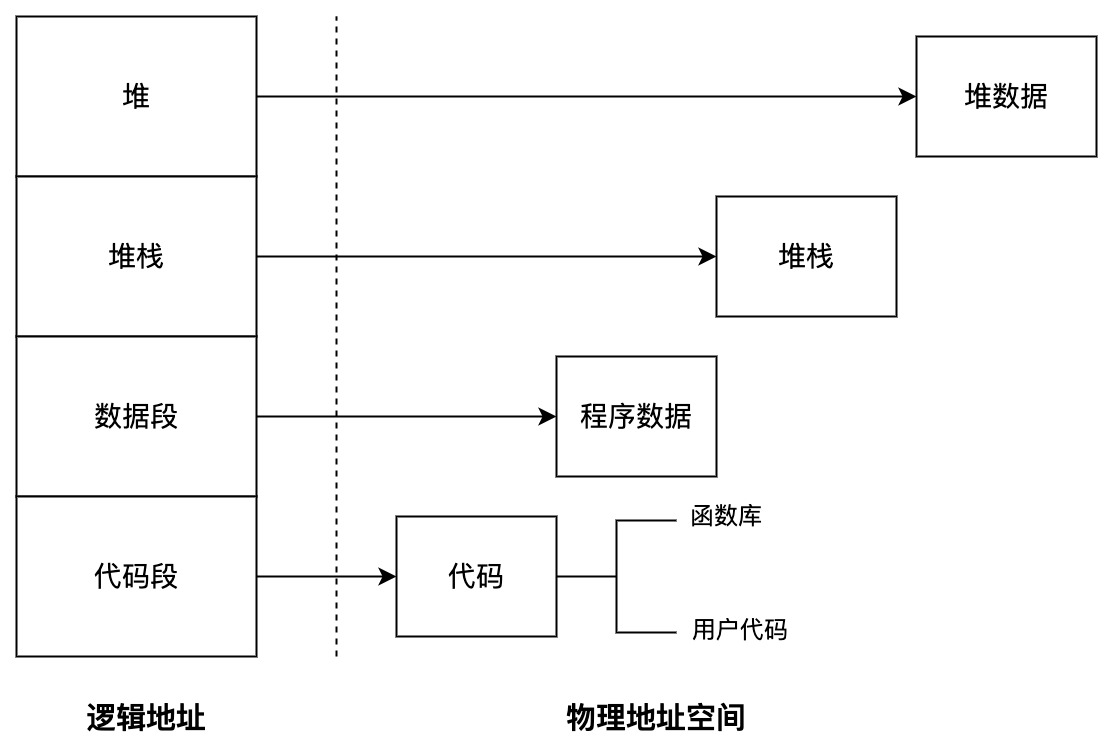
另外,它们各个部分内部连续,但之间相对去耦合,从而实现(这里是相对底层的)复用。这和高级语言编程中加入函数和模块的考量是一致的。
那么段式存储管理是如何访问的呢?
分段存储是通过偏移量来访问不同的块,其实在不同块之间的访问转化成本并不是很高。这样就在一定开销的情况下实现了共享,同时增加了内存利用率。主要是利用基址+长度这种描述方法访问段的地址。段的地址可以用一个二元数来表示,其中一个是基址,原理上基址加指定的偏移,就可以完成重定位,即可找到段的地址。 二元数的另一个元素是长度,在重定位之前就要验证段长度是否会溢出。
分页存储管理(paging)
页式存储和段式存储是两种不同粒度的管理策略,但是其总体思路是一致的,认识如下量方面即可:
- 单元划分的标准
- 单元访问方式
页式存储管理的基本单元
将分块进行较小的划分之后,由于数量增多,我们希望这种效率提高,基于二进制的位运算是符合这种目标的。 我们将 2 的 n 次方的内存片段作为页式存储的单元,如 512、4k、8k,4k 是很常见大小。
- 物理地址空间中的单元叫做物理页面,一般地,称为页帧(page frame),简称帧(frame)。
- 逻辑地址空间中的单元称为逻辑页面,一般地,称为页面,简称页(page)。
- 帧和页的大小必须相同。
页式存储的地址转换
首先看物理内存中的单元:帧。物理内存被划分为 2 的 n 次方大小的帧,其内存物理地址仍然可以用二元组(f, o)表示,f 为帧号(占 s 位),o 为偏移。 则物理地址为:$f\times2^S + o$
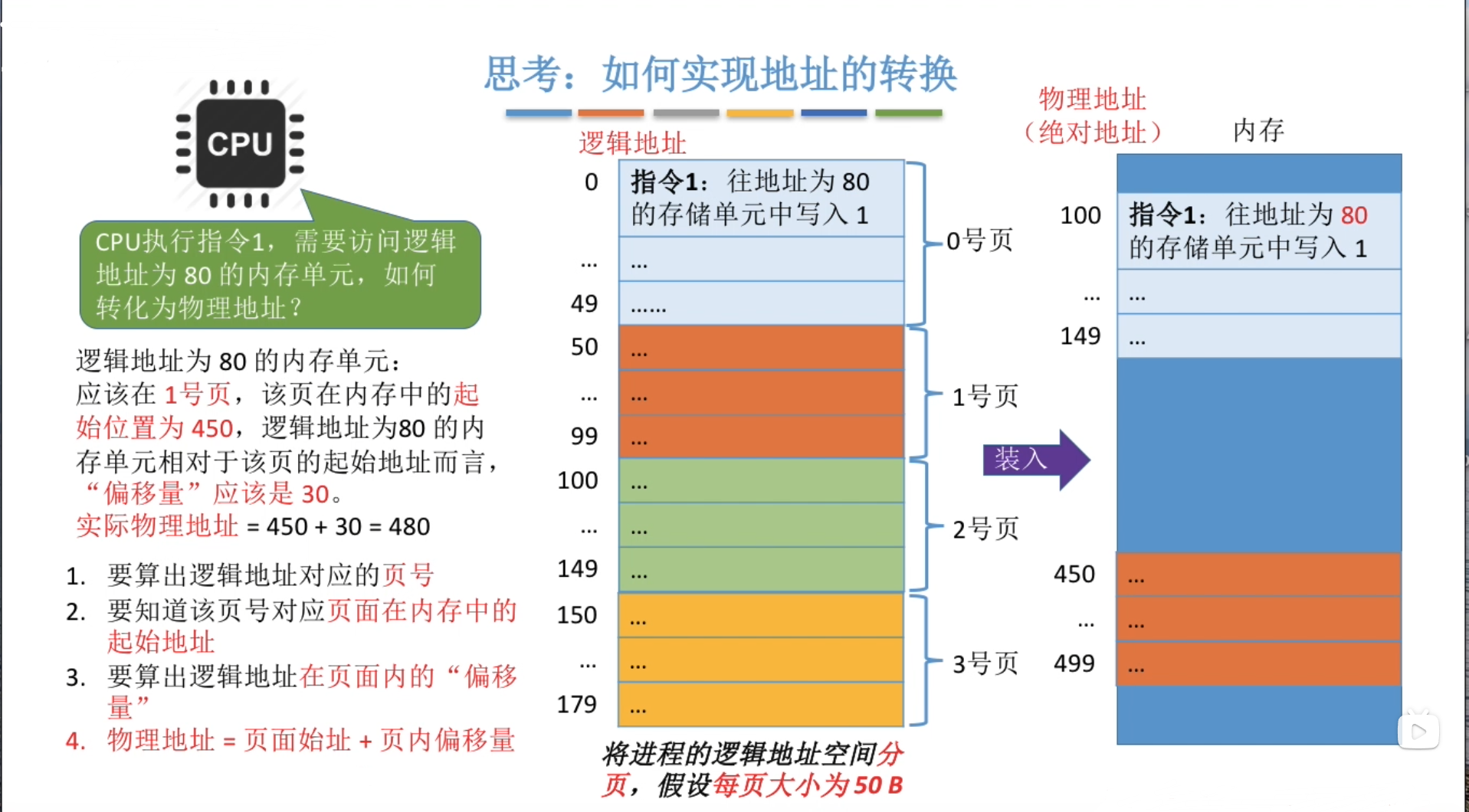
页和帧有一定的对应关系,在两个对应的页和帧中,页内偏移和帧内偏移一致,但通常页号大小和帧号大小不同。构建的逻辑地址合乎人的使用习惯,页号是连续的。而物理地址空间中的帧号并不是连续的。
页表
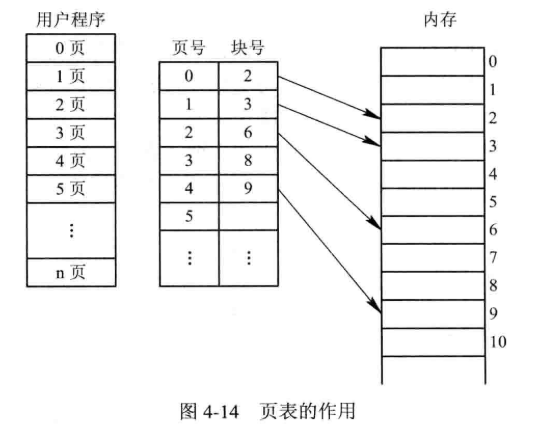
概念:
- 每个进程都有一个页表,每一个页面都有一个页表项。
- 页表是按照逻辑页密排的,所以页号并不需要存入页表项。
- 页表项中只储存物理帧号以及一些标志位。
- 页表中的内容随着进程的运行状态而动态变化。为了表征这些变化所以引入标志位,比如存在位、修改位、引用位等。
例子:假定一个 16 位系统,物理内存 32KB,页大小 1k,则 有 32 页。0~9 存储页内数据,A~F 存储页号。
- 页表有 32 项。
- 物理帧号的地址位数一般少于逻辑地址,因为并不是进程的每一个页面都要调入内存,所以物理帧号的位数小于页号位数。
解决页式存储管理的问题:
- 需要访问两次:使用缓存(快表)
- 页表可能非常大:间接访问(多级页表)
快表
快表(TLB,Translation Look-aside Buffer)就是将最近使用过的页表存入 CPU,使用 caching 的方式加快页表的查询对应。
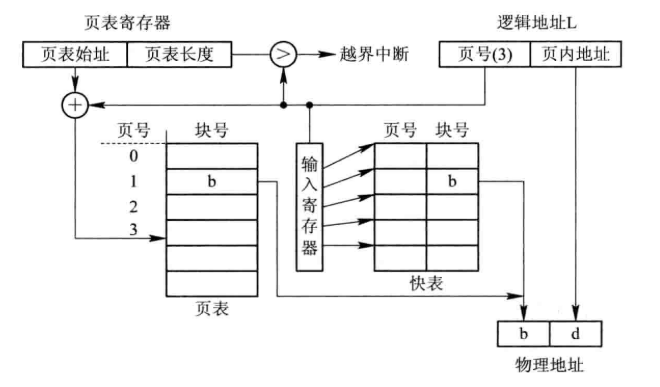
如果 TLB 命中,则物理页号将会快速且并行地获取;未命中时查询页表,随后更新 TLB。若命中率高,那么 TLB 对于页表查询开销的改善作用是非常有效的。
多级页表
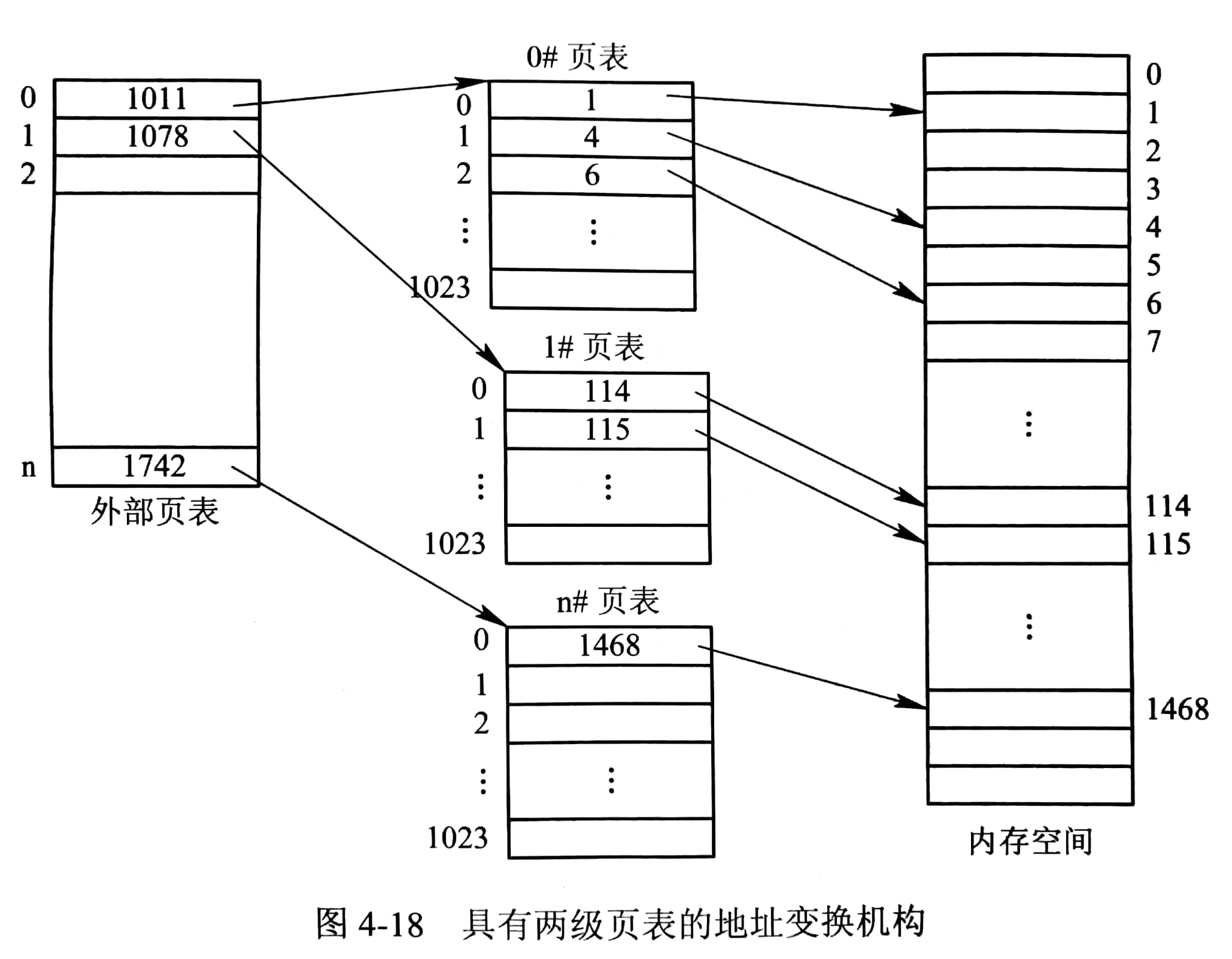
将线性页表转换为树形结构,即可构建多级页表,可以减小每一级的长度。如果逻辑地址空间全满的话,对于存储空间来说,其实并没有非常显著的提升,但是实际使用过程中,会有很多空的分支,这样就可以节省一部分空间。即对应时间换空间的概念。
反向页表
由于多级页表是树形结构,虚拟空间膨胀会很快,对于大地址空间,多级页表仍会变得非常繁琐。 为了克服这个指数爆炸的效应,我们从虚拟的逻辑空间中走出来,着眼于有限的物理空间,以物理地址空间为抓手建立索引。这就是页寄存器和反置页表的思路。
在这种情况下,如果页面本身相对于页表项很大的话,页表的内存开销就不足为惧了。
具体的实现方法是,让每一个物理帧都和一个页寄存器相关联。页寄存器包含如下的标志位:
- 使用位(residence bit):此帧是否被进程占用
- 占用页号(occupier):对应的页号 p
- 保护位(protection bits)
这种方法的好处在于:
- 大大减省页表占用内存
- 页表大小与逻辑地址空间相比往往很小
缺点在于其反转了逻辑,要能够依据帧号找页号(建立联系),同时在用页号查找时就相对困难。
- 如上的联系通过哈希的方法建立,对逻辑地址进行哈希,随后就可以在页寄存器反向建立的查找表中进行小范围查找。
- 这里还可以引入快表,尽管快表功耗大
- 如果有冲突需要遍历冲突项
参考
许可协议: 署名-非商业性使用-禁止演绎 4.0 国际 转载请保留原文链接及作者。